
When you are working on an embedded device, you usually start simple. A main loop that does something.
As you start to add more features, the complexity of the code grows. You add more ifs, more loops, more conditions, and even, god forbid, switch statements.
This is the point when you should to pause and ask yourself: "Am I doing the right thing?"
There must be a better way...
Better way to make these kind of systems, which is not tangled, hard to debug and hardly testable.
For you I present: The State Machine
A State machine is a pretty common pattern which allows you to implement event driven systems. It presents a simple solution which will allow you, dear developer, to create very complex and yet maintainable system.
What is a State Machine?
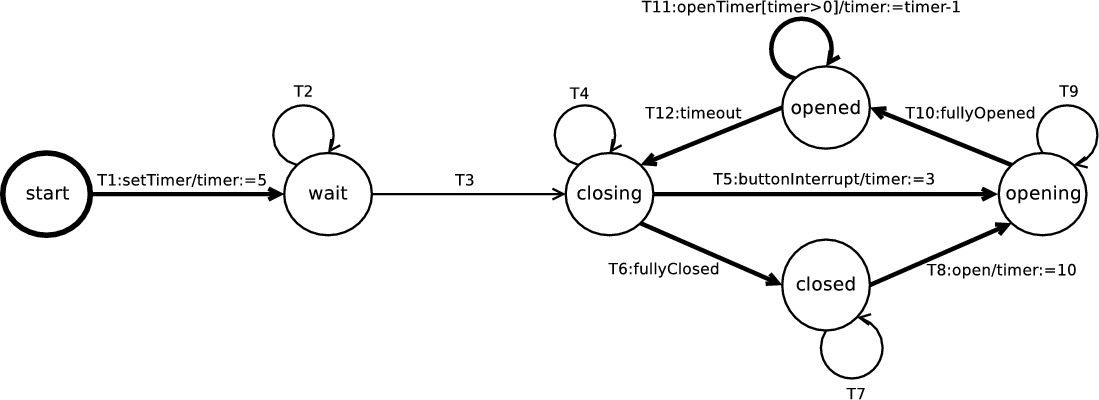
A Finite State Machine (FSM) describes a system that can be in one of pre-defined number of states.
The machine can only be in one state at a time. This state is called the current state.
The machine can move from one state to another as a result of an event or condition.
This is called a Transition.
A specific FSM is defined by a collection of its states and the transitions between them.
Think of a State Machine as a directed graph, where the states are the nodes and the transitions are the edges:
Naive approach
Let define the interface for a state:
class IState
{
public:
virtual IState* Run() = 0;
}
Here, each state in the system "knows" what will be the next state in line.
So when a state is done it returns an instance of that state:
class BootState :: IState
{
public:
IState* Run()
{
// Do something
return new StandByState();
}
}
The main loop should look something like this:
void main()
{
IState *currentState = new BootState();
while(true)
{
IState *nextState = currentState->Run();
delete currentState;
currentState = nextState;
}
}
Simple, isn't it?
This solution is pretty simple and you can find a lot of variation of it in several open sources, but the simplicity hides several issues.
Maintainability
Imagine a system with 10 states, each state is implemented the way I described earlier.
Now, imagine you, trying to explain to someone how the graph looks like without tracing/debugging the code.
Also, imagine that each state can lead to several states...
Here, in order to understand the system you actually need to jump class by class and look at all the code paths, all the ifs in the states in order to understand which state lead to which states.
And as your project grows, it becomes extremely difficult to understand the whole the system, and even more to understand where can a bug originate.
OCPish
At first look it seems this code comply with Open-Closed principle.
Its actually not.
What if you want to add a state in the middle of the graph?
You'll have to change an existing state in order to do it.
You need to know what is the preceding state and what is the state after it.
That's a lot of existing code to change
Memory
Yes, you heard me. In embedded system you need to take care of memory.
Here since we allocate and deallocate classes from the heap every time we transition between states we cause the heap to be fragmented very fast.
Since most embedded OSs don't take care of memory fragmentation, you can run out of memory very fast.
So what have we learned?
We want our state machine mental graph to be easy to understand without tracing/debugging.
We want our state machine to allow us to add states and transitions very easily while making the state themselves comply with SOLID.
And we want to be able to do that with proper memory allocation.
Let's try that again
State Machine is complied from states and transitions.
So lets add a definition of a Transition:
class ITransition
{
}
Now lets revise IState a bit:
class IState
{
public:
virtual ITransition* Run() = 0;
}
Now, each state returns a transition.
Someone needs to "know" to where this transition will lead.
We need a map that connects each transition with the next state. That's a perfect job for the State Machine itself.
So now, lets add a class for the State Machine:
// StateMachine.h
using <map> // map from STL
class StateMachine
{
public:
StateMachine(std::map<ITransition*, IState*> *transitions, IState* initialState);
void Run();
private:
std::map<ITransition*, IState*> *_transitions;
IState* _currentState;
}
// StateMachine.cpp
using <StateMachine.h>
StateMachine::StateMachine(std::map<ITransition*, IState*> *transitions, IState* initialState)
{
_transitions = transitions;
_currentState = initialState;
}
void StateMachine::Run()
{
ITransition *transition;
while(true)
{
transition = _currentState->Run();
_currentState = (*_transitions)[transition];
}
}
Now, our main should prepare the specific state machine, creating a map of all the states and transitions, and run the state machine:
void main()
{
BootState initialState;
std::map<ITransition*, IState*> transitions;
/* BootState -> */ transitions[ConfiguredTransition::GetInstance(), new StandByState()];
...
StateMachine *stateMachine = new StateMachine(&transitions, &initialState);
stateMachine->Run();
}
Is this better?
Lets go over our requirements and understand if we did something good here.
Mental model
The state and transitions are very readable by looking at building of the the transitions map. From it you can easily describe the graph without traveling through a lot of files.
One issue is the source state, which I used a comment in order to describe it.
In order to do it in code I needed to create a tuple as the map key, and it seems and overkill for this. Of course you can do it if you think it gives you an added value.
Easy to add
Single Responsibility Principle
Each state now only knows its own logic and can only generate transitions that will lead to state changes.
The state machine itself causes the state change.
Each component is responsible for doing its own thing.
Open Closed Principle
Here is when it gets complicated...
Adding a new state requires you to create a new class.
Incorporating the new state requires you to add it to the transition map. This seems like a violation of this principle. And it is.
But, the one thing that cannot be OCPied is ordering. Which is the case here. Order by itself can not be OCP - since you need to "know" other components in the system.
What we did here just makes it less complex to add or change. You only need to add it in one place. The same place every time - the state machine building. You don't need to change existing states.
Also, its important to know that a new transition requires you to change an existing state. In this case its actually changes the way in existing state behaves, so it kinda makes sense.
Memory
Yes, we are still working on the heap.
But, we allocate all of our states and transitions in the beginning of our run, making them allocated in the beginning of the heap.
Since all of our states are known (the definition of FSM), it makes perfect sense to allocate them all and to travel on them.
Also, note since we use transitions in the map but also in the states (since they need to return the transition), each transition is in fact a singleton (note the GetInstance method), making them allocated together with all the states.
So the entire state machine is allocated in one big pile of memory in the beginning of the heap.
The Granularity Issue
Is everything a state?
Does everything needs to be managed in the state machine?
These are interesting questions that starts to pop up as your system continues to grow.
You can create a state for every if in your code. But then, the graph becomes so complex making it, again, very hard to maintain even if you know the whole structure.
The graph is so granular that its very hard to understand what is a main flow and what is an artifact or a building block.
A better solution is to map the high level states. The basic pillars of the system. The main flows.
Internally each of these state can be a straightforward flow (ifs and all) or a small state machine by itself.
The point is to allow you to look at high level and then zoom in into a specific flow and understand it specifically.
What's next?
There are a couple more cases I didn't discuss here, like cleanup of a state, payload between states and default state.
You can find these and more at github.
I hope you can use this solution on your next project in order to create a good, maintainable codebase.